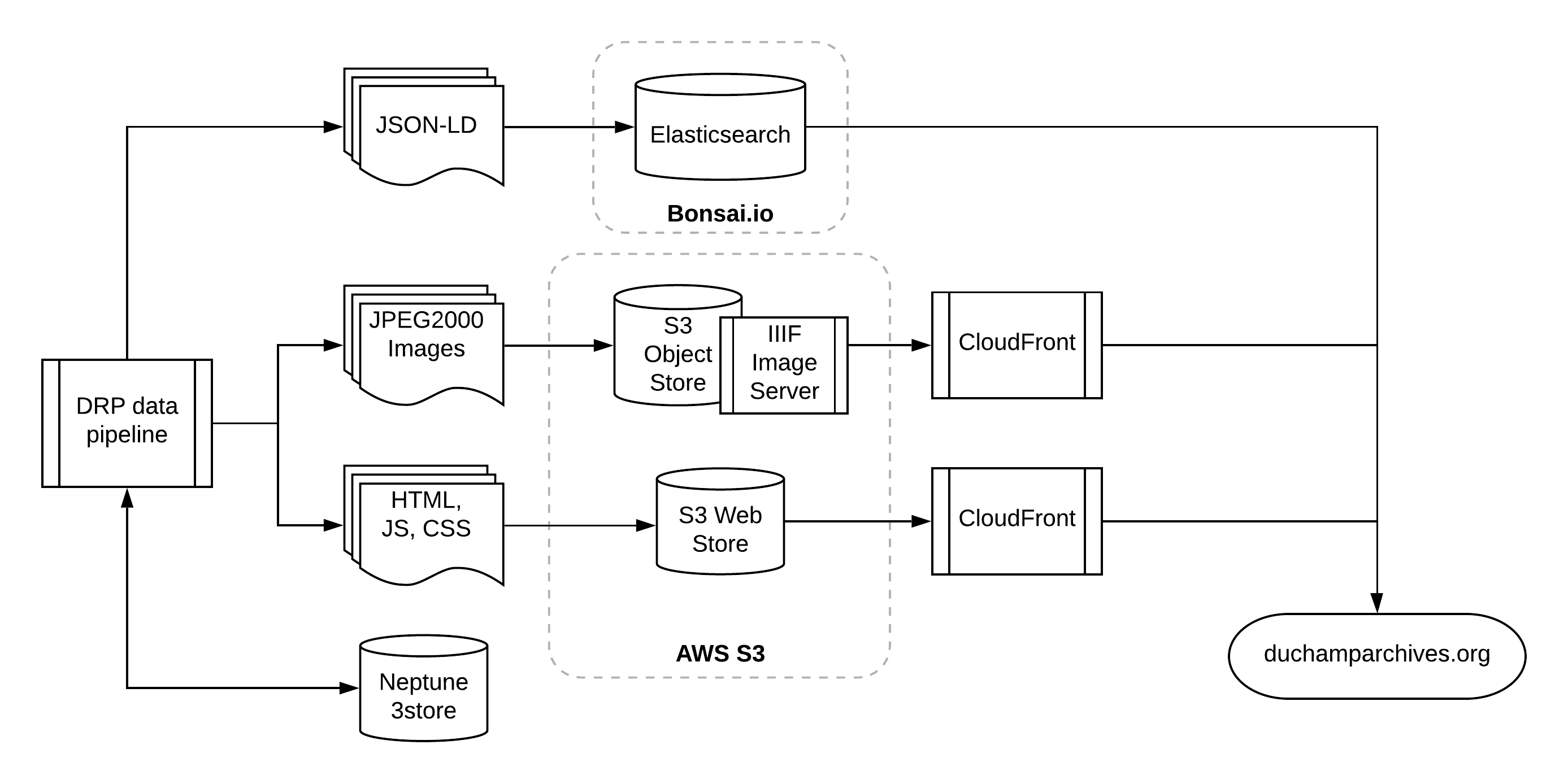
The Duchamp Research Portal Data Pipeline consists of three layers of data handling:
Tabular data layer (selection, validation, escaping) --> Linked data layer (reconciliation, flattening, composition) --> Presentation layer (browse, search, display)
Likewise there is an image layer that takes source images from an institution's web-available links and a repository of source images in AWS. These source images are compressed to JPEG2000:
Uncompressed and unnormalized source images (TIFF, JPEG) --> Presentation layer (JPEG2000)
Each of these layers use a few specific frameworks glued together with some basic plumbing code (written in Python) to move data between systems, manage the linked data graph, and prepare data for display:
Data is moved between these stores with a basic pipeline written in python that runs loading, transform, and export jobs through a simple queue that provides parallel execution. The command line options and structure use click, the processing queue uses Queues and a Pool from python's multiprocessing library, and linked data transforms and RDF generation are handled using the bulk RDF generator from USC-ISI's Karma project and (for some data types) Python's CSVW package. Image normalization is done in Pillow and JPEG2000 compression is executed with OpenJPEG. For a detailed breakdown of the pipeline stack, take a look at the collections app code.
For generating the site from linked data, we use a few custom mapping classes that feed simplified JSON documents to HTML generators with Jinja2 templates and a few simple Elasticsearch management tools that use elasticsearch-py. For more information on the site generator, take a look at the collections app site generator code.
For deployment and production site generation we use a GitHub repository that automatically generates the front-end code on commit and publishes to a Netlify site.